tech.agilitynerd search
Haystack Search Result Ordering and Pre-Rendering Results
I use Haystack and the Python Whoosh project to provide search over ~3400 articles in my Googility.com database. I had originally implemented the search in the "simplest way that works". I was making some other enhancement to Googility and noticed the search result page had two undesirable behaviors:
- The …
Improving Google Ads and Google Search Descriptions
I was looking at the google search results for my Googility web site and noticed that the descriptions shown underneath the title often contained text from my navigation links instead of content from the body of the page:
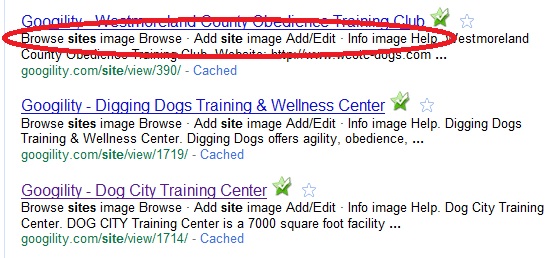
I did some searching and found the Google Webmaster blog post about …